인공지능(AI) 기술이 모든 산업군의 백엔드와 프론트엔드에 깊숙이 침투하면서, 이제 개발자에게 AI 활용 능력은 단순한 ‘우대 사항’을 넘어 ‘필수 역량’으로 자리 잡고 있습니다. 다양한 AI 자격증 중에서 실무 활용도와 코딩 능력을 동시에 검증하는 AICE(AI Certificate for Everyone)는 특히 개발자들 사이에서 그 효용성을 인정받고 있습니다. 본 포스팅에서는 현직 개발자 관점에서 AICE Associate와 Professional 등급을 준비하고 합격하는 과정에서 얻은 실질적인 노하우와 전략을 상세히 분석합니다.
AICE 자격증 개요와 개발자가 주목해야 할 이유
AICE란 무엇인가?
AICE는 KT가 개발하고 한국경제신문이 주관하는 인공지능 자격증으로, 단순히 이론적인 지식만을 묻는 것이 아니라 실제 데이터셋을 다루고 모델을 구축하는 ‘실기 위주’의 평가 방식을 채택하고 있습니다. 이는 텐서플로우(TensorFlow), 파이토치(PyTorch), 사이킷런(Scikit-learn) 등 현업에서 가장 많이 사용되는 라이브러리를 활용해 문제를 해결해야 하므로, 실무 역량을 증명하기에 매우 적합합니다.
등급별 특징 및 타겟
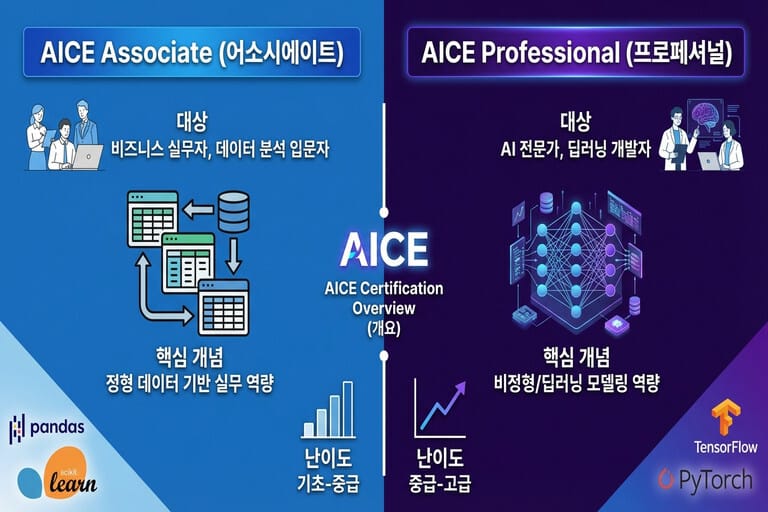
AICE는 Basic, Associate, Professional 등 크게 세 가지 레벨로 나뉩니다. 개발자라면 Basic은 건너뛰고 Associate부터 시작하거나, 머신러닝/딥러닝에 대한 이해도가 있다면 바로 Professional에 도전하는 것이 일반적입니다.
- Associate: 준전문가 과정입니다. 주로 정형 데이터(Tabular Data)를 다루며, 데이터 전처리부터 머신러닝 모델링, 결과 해석까지의 과정을 평가합니다. Python 라이브러리(Pandas, Scikit-learn, Matplotlib) 활용 능력이 핵심입니다.
- Professional: 전문가 과정입니다. 정형 데이터뿐만 아니라 비정형 데이터(이미지, 텍스트 등)를 포함하여 딥러닝 모델을 설계하고 최적화하는 능력을 봅니다. TensorFlow나 PyTorch를 능숙하게 다룰 수 있어야 합니다.
AICE Associate vs Professional 상세 비교 분석
두 등급은 난이도와 다루는 범위에서 명확한 차이를 보입니다. 본인의 현재 스킬셋에 맞춰 전략적인 선택이 필요합니다.
| 구분 | Associate | Professional |
|---|---|---|
| 주요 대상 | 데이터 분석 입문 개발자, 비전공자 | AI/ML 엔지니어, 데이터 사이언티스트 |
| 시험 시간 | 90분 | 120분 |
| 문항 수 | 14문항 내외 | 10문항 내외 |
| 핵심 기술 | Pandas, Scikit-learn, Seaborn | TensorFlow/PyTorch, CNN, RNN, NLP |
| 데이터 유형 | 정형 데이터 (CSV 등) | 정형 + 비정형 (이미지, 텍스트) |
| 평가 방식 | 빈칸 채우기, 코드 수정, 부분 코딩 | 모델 아키텍처 설계, 하이퍼파라미터 튜닝 |
등급별 핵심 공략 가이드
Associate 공략: 데이터 전처리가 합격의 열쇠
Associate 시험은 머신러닝 모델의 복잡도보다는 데이터를 모델에 넣기 좋게 가공하는 전처리 능력을 중점적으로 봅니다.
필수 학습 라이브러리
- Pandas:
read_csv,fillna,dropna,get_dummies(원-핫 인코딩),replace,map등의 함수는 눈 감고도 칠 수 있을 정도로 익숙해져야 합니다. - Scikit-learn:
train_test_split,MinMaxScaler/StandardScaler, 그리고 기본적인 분류/회귀 모델(DecisionTreeClassifier,RandomForestRegressor)의 호출 및fit,predict,score메서드 사용법을 익혀야 합니다.
주의해야 할 함정
결측치 처리를 할 때 문제에서 요구하는 방식(평균값 대치, 삭제, 최빈값 대치 등)을 정확히 따라야 합니다. 또한, 범주형 데이터를 수치형으로 변환하는 라벨 인코딩(Label Encoding)과 원-핫 인코딩(One-hot Encoding)의 차이를 명확히 구분하여 적용해야 감점을 피할 수 있습니다.
Professional 공략: 모델 아키텍처 암기와 활용
Professional 등급은 딥러닝의 영역입니다. 단순히 라이브러리를 호출하는 것을 넘어, 층(Layer)을 쌓고 모델을 컴파일하며 학습 과정을 제어하는 능력이 요구됩니다.

딥러닝 프레임워크 선택
TensorFlow(Keras)와 PyTorch 중 하나를 선택할 수 있습니다. 일반적으로 코드가 직관적이고 API가 정형화된 TensorFlow(Keras)를 추천합니다. 시험장에서는 공식 문서를 참고할 수 없거나 제한적이므로, 모델 구조를 짜는 코드는 외워가는 것이 유리합니다.
주요 출제 유형 대비
- 이미지 분류 (CNN):
Conv2D,MaxPooling2D,Flatten,Dense레이어로 이어지는 기본 구조를 마스터해야 합니다. 또한,ImageDataGenerator를 이용한 데이터 증강(Augmentation) 기법도 자주 출제됩니다. - 시계열/텍스트 분석 (RNN/LSTM):
Embedding레이어와LSTM또는GRU레이어를 활용한 모델링 연습이 필요합니다. - 전이 학습 (Transfer Learning): VGG16, ResNet50 등 사전 학습된 모델(Pre-trained Model)을 불러와서 Fine-tuning 하는 코드를 작성할 수 있어야 합니다.
실전 코드 예시로 보는 합격 전략
실제 시험 환경은 주피터 노트북(Jupyter Notebook) 기반입니다. 다음은 등급별로 반드시 숙지해야 할 코드 패턴입니다.
Associate 레벨: 전처리 파이프라인
데이터 분석의 기초인 결측치 처리와 인코딩 예제입니다. 문제에서 “결측치는 평균으로, ‘Category’ 컬럼은 원-핫 인코딩하시오”라고 했을 때 즉각적으로 작성할 수 있어야 합니다.
import pandas as pd
from sklearn.model_selection import train_test_split
# 1. 데이터 로드
df = pd.read_csv('data.csv')
# 2. 결측치 처리 (Age 컬럼의 평균으로 대치)
df['Age'] = df['Age'].fillna(df['Age'].mean())
# 3. 불필요 컬럼 삭제
df = df.drop(['ID', 'Name'], axis=1)
# 4. 범주형 데이터 원-핫 인코딩 (drop_first=True로 다중공선성 방지 고려)
df = pd.get_dummies(df, columns=['Category'], drop_first=True)
# 5. 데이터 분할
X = df.drop('Target', axis=1)
y = df['Target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("전처리 완료:", X_train.shape)
Professional 레벨: 딥러닝 모델링
이미지 분류를 위한 간단한 CNN 모델 설계 예제입니다. Sequential API를 사용하여 층을 쌓고, compile과 fit을 수행하는 전체 흐름을 이해해야 합니다.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
# 1. 모델 아키텍처 설계
model = Sequential([
# Convolution Layer: 특징 추출
Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
# Fully Connected Layer: 분류
Flatten(),
Dense(128, activation='relu'),
Dropout(0.5), # 과적합 방지
Dense(10, activation='softmax') # 10개 클래스 분류
])
# 2. 모델 컴파일 (Optimizer, Loss Function 설정 중요)
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 3. 모델 학습 (EarlyStopping 콜백 활용 권장)
early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=3)
# history = model.fit(X_train, y_train, validation_data=(X_val, y_val),
# epochs=10, callbacks=[early_stop])
시험 당일 팁과 주의사항
AIDU 환경 적응
AICE 시험은 KT의 클라우드 기반 AI 플랫폼인 ‘AIDU’ 환경에서 치러집니다. 로컬 주피터 노트북과 유사하지만, 단축키가 미세하게 다르거나 네트워크 속도에 따라 셀 실행 반응이 느릴 수 있습니다. 시험 시작 전 제공되는 오리엔테이션 시간에 환경 설정을 꼼꼼히 확인해야 합니다.
시간 관리 전략
- 오류 해결에 매몰되지 말 것: 코드가 실행되지 않을 때 5분 이상 원인을 찾지 못하면 일단 다음 문제로 넘어가세요. 부분 점수가 있기 때문에 완벽한 한 문제보다 여러 문제의 기본 코드를 작성하는 것이 유리합니다.
- 복사/붙여넣기 활용: 앞 문제에서 작성한
import구문이나 전처리 코드는 뒤 문제에서도 재사용되는 경우가 많습니다. 효율적으로 코드를 복사해서 시간을 단축하세요. - 저장 습관: 클라우드 환경 특성상 연결이 불안정할 수 있으므로, 주기적으로
Ctrl + S를 눌러 저장하는 습관을 들여야 합니다.
AICE 자격증의 실무 가치
AICE 자격증은 단순히 이력서에 한 줄을 추가하는 용도가 아닙니다. 준비 과정을 통해 다음과 같은 실질적인 이득을 얻을 수 있습니다.
- AI 파이프라인의 전체 이해: 데이터 로드부터 전처리, 모델링, 평가까지 이어지는 AI 개발의 A to Z를 직접 코딩하며 체화할 수 있습니다.
- 라이브러리 숙련도 향상: 평소 습관적으로 복사해서 쓰던 코드들을 직접 타이핑하며, 각 파라미터가 모델 성능에 미치는 영향을 깊이 있게 이해하게 됩니다.
- 개발자 커리어 확장: 백엔드/프론트엔드 개발자가 AI 엔지니어링 지식을 갖추면, AI 모델 서빙이나 MLOps 분야로 커리어를 확장하는 데 큰 도움이 됩니다.
자격증 취득은 끝이 아니라 시작입니다. AICE를 통해 다진 기초 체력을 바탕으로 캐글(Kaggle) 컴피티션에 참여하거나, 실제 토이 프로젝트에 AI 모델을 적용해보며 실력을 확장해 나가시길 바랍니다.