안녕하세요.
시스템을 운영하다 보면 “기존 테이블의 데이터를 읽어서, 포맷을 변경하거나 계산을 수행한 뒤, 새로운 테이블(또는 통계 테이블)에 적재”해야 하는 일이 빈번합니다. 이를 흔히 ETL(Extract, Transform, Load) 작업이라고 부릅니다.
오늘은 Spring Batch의 JpaPagingItemReader와 JdbcBatchItemWriter를 조합하여 가장 안정적이고 성능이 좋은 DB 간 데이터 이관 배치를 만들어 보겠습니다.
1. 시나리오 및 아키텍처
우리는 쇼핑몰의 Order(주문) 테이블에서 데이터를 읽어, 주문 금액에 따른 포인트를 계산한 뒤 OrderHistory(주문 이력) 테이블에 저장하려고 합니다.
- Source:
Order(JPA Entity로 조회) - Process: 주문 금액의 1%를 포인트로 계산, 주문 상태 코드를 한글명으로 변환
- Target:
OrderHistory(JDBC로 Bulk Insert)
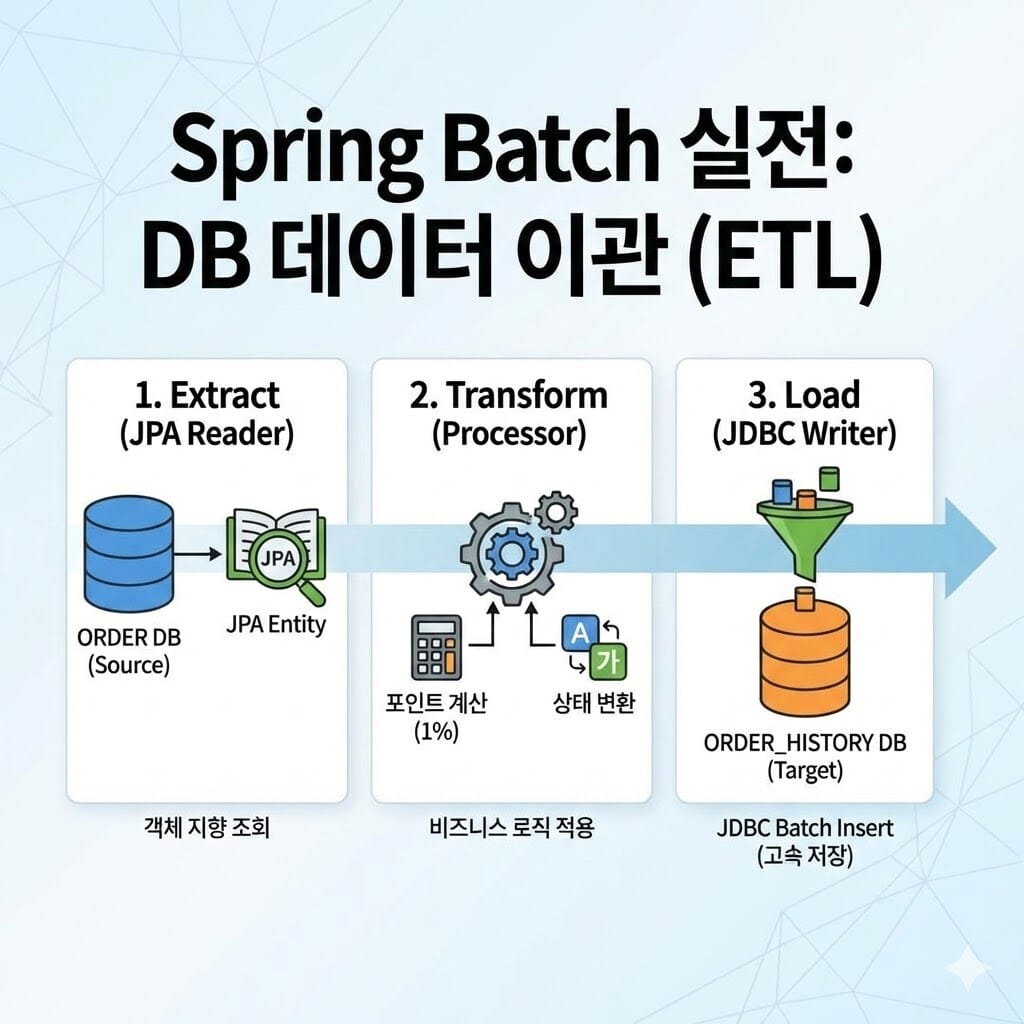
이 구조는 읽을 때는 객체지향적인 편리함(JPA)을 누리고, 쓸 때는 대용량 처리 성능(JDBC)을 챙기는 실무 최고의 조합 중 하나입니다.
2. 도메인 및 테이블 구조
2.1 Source Entity (Order)
@Entity
@Getter
@Table(name = "ORDERS")
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String customerName;
private BigDecimal totalAmount;
private String status; // "PAID", "CANCEL"
private LocalDateTime orderDate;
}
2.2 Target DTO (OrderHistory)
JPA Entity가 아닌 DTO로 정의합니다. Writer가 JDBC를 사용하기 때문입니다.
@Getter
@Setter
@AllArgsConstructor
public class OrderHistoryDto {
private Long originalOrderId;
private String customerName;
private BigDecimal rewardPoints; // 계산된 포인트
private String statusDescription; // 변환된 상태 설명
private LocalDateTime processedAt; // 배치 처리 시간
}
3. 핵심 배치 코드 (Job Configuration)
@Configuration
@RequiredArgsConstructor
public class OrderMigrationJobConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final EntityManagerFactory emf; // JPA Reader용
private final DataSource dataSource; // JDBC Writer용
private static final int CHUNK_SIZE = 100;
@Bean
public Job orderMigrationJob() {
return new JobBuilder("orderMigrationJob", jobRepository)
.start(orderMigrationStep())
.build();
}
@Bean
public Step orderMigrationStep() {
return new StepBuilder("orderMigrationStep", jobRepository)
.<Order, OrderHistoryDto>chunk(CHUNK_SIZE, transactionManager)
.reader(orderReader())
.processor(orderProcessor())
.writer(orderHistoryWriter())
.build();
}
// 1. Reader: JPA를 사용하여 페이징 방식으로 읽기
@Bean
public JpaPagingItemReader<Order> orderReader() {
return new JpaPagingItemReaderBuilder<Order>()
.name("orderReader")
.entityManagerFactory(emf)
.pageSize(CHUNK_SIZE)
.queryString("SELECT o FROM Order o WHERE o.status = 'PAID'") // 결제 완료된 건만 조회
.build();
}
// 2. Processor: 비즈니스 로직 (데이터 가공)
@Bean
public ItemProcessor<Order, OrderHistoryDto> orderProcessor() {
return order -> {
// 포인트 계산 (1%)
BigDecimal points = order.getTotalAmount().multiply(new BigDecimal("0.01"));
// 상태 코드 변환
String statusDesc = "결제완료"; // 예시로 단순화
return new OrderHistoryDto(
order.getId(),
order.getCustomerName(),
points,
statusDesc,
LocalDateTime.now()
);
};
}
// 3. Writer: JDBC Batch Update로 고성능 저장
@Bean
public JdbcBatchItemWriter<OrderHistoryDto> orderHistoryWriter() {
return new JdbcBatchItemWriterBuilder<OrderHistoryDto>()
.dataSource(dataSource)
.sql("INSERT INTO ORDER_HISTORY (original_order_id, customer_name, reward_points, status_description, processed_at) " +
"VALUES (:originalOrderId, :customerName, :rewardPoints, :statusDescription, :processedAt)")
.beanMapped()
.build();
}
}
4. 왜 Reader는 JPA고 Writer는 JDBC인가요?
이 질문이 가장 중요합니다.
- Reader (JPA): 데이터를 읽어올 때는 복잡한 연관관계(예: 주문 -> 주문상품 -> 상품)를 다뤄야 할 때가 많습니다. JPA를 쓰면 객체 그래프 탐색이 쉬워 비즈니스 로직 구현이 간편합니다.
- Writer (JDBC): 반면, 저장은 보통 ‘통계 테이블’이나 ‘이력 테이블’ 같은 단순 구조인 경우가 많습니다. JPA의
saveAll()도 좋지만, 수십만 건을 넣을 때는 JDBC의 Batch Insert가 훨씬 빠르고 메모리도 덜 먹습니다.

5. 주의사항 및 팁
5.1 영속성 컨텍스트 관리
JpaPagingItemReader는 페이지를 읽을 때마다 영속성 컨텍스트를 초기화하지 않으면 메모리 누수가 발생할 수 있습니다. 다행히 Spring Batch 구현체 내부적으로 페이지 단위 초기화를 수행하지만, Processor에서 연관 엔티티를 무리하게 로딩(Lazy Loading)하다가 LazyInitializationException이 발생하지 않도록 주의해야 합니다. (Reader 쿼리에서 JOIN FETCH 사용 권장)
5.2 Chunk Size와 Page Size 일치
JPA Paging Reader를 쓸 때는 반드시 Chunk Size와 Page Size를 동일하게 설정하세요. 다르면 불필요한 조회 쿼리가 더 나가거나 페이징 로직이 꼬일 수 있습니다.
6. 결론
DB to DB 마이그레이션은 “읽기 -> 가공 -> 쓰기”의 정석입니다.
오늘 소개한 JPA Reader + JDBC Writer 패턴은 실무에서 성능과 개발 편의성 두 마리 토끼를 잡는 가장 표준적인 패턴이므로, 꼭 숙지해 두시기 바랍니다.