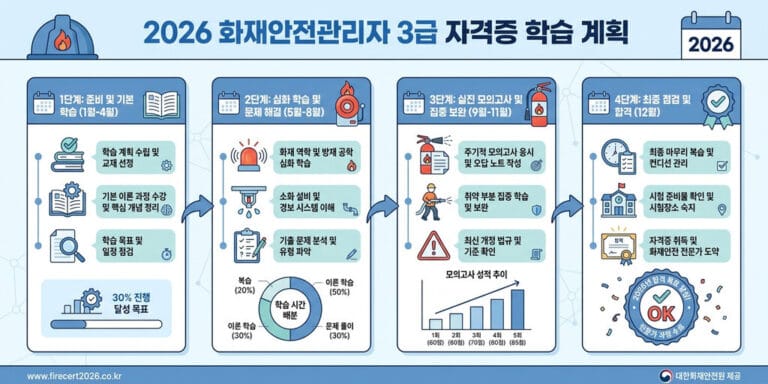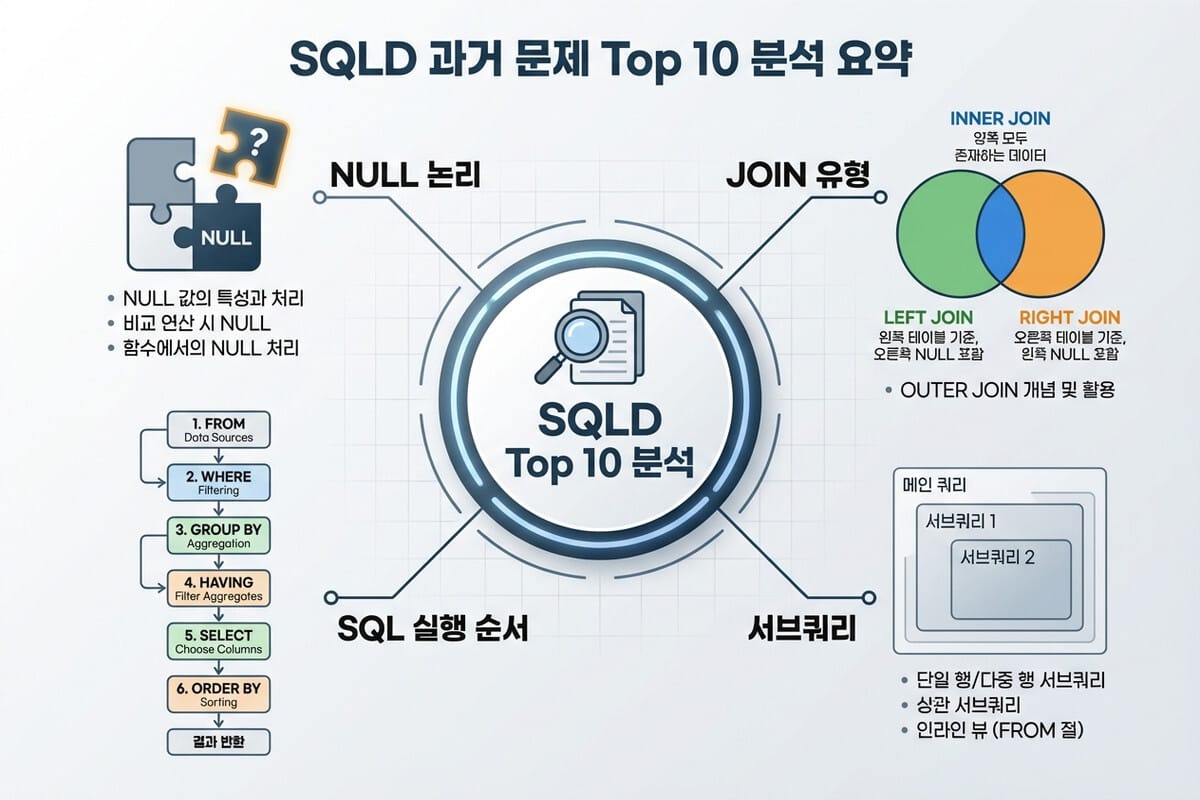
국가공인 SQL 개발자(SQLD) 자격증 시험은 데이터베이스 모델링 이론부터 실무 SQL 작성 능력까지 폭넓은 지식을 요구합니다. 하지만 수년간의 기출문제를 분석해 보면, 합락을 가르는 핵심 문제들은 특정 유형에서 반복적으로 출제된다는 패턴을 발견할 수 있습니다. 방대한 양의 이론서를 무작정 암기하기보다는, 출제 빈도가 높고 오답률이 높은 핵심 유형 10가지를 완벽하게 파악하는 것이 단기 합격의 지름길입니다. 본 포스트에서는 SQLD 시험에 가장 자주 등장하는 SQL 패턴 10가지를 선정하여 심도 있게 분석하고, 각 유형별 함정과 풀이 전략을 제시합니다.
1. NULL의 특성과 3가 논리(Three-Valued Logic)
SQLD 시험에서 가장 기본적이면서도 수험생들이 가장 많이 실수하는 영역이 바로 NULL 처리에 관한 문제입니다.
NULL의 정의와 연산 법칙
NULL은 ‘0’이나 ‘공백(Space)’과는 완전히 다른 개념입니다. ‘아직 정의되지 않은 값’ 또는 ‘알 수 없는 값’을 의미합니다. 이 특성 때문에 NULL이 포함된 산술 연산의 결과는 무조건 NULL이 됩니다.
- NULL + 숫자 = NULL: 아무리 큰 숫자를 더해도 결과는 알 수 없습니다.
- NULL 비교 연산:
col1 = NULL은 잘못된 문법입니다. 반드시IS NULL또는IS NOT NULL을 사용해야 합니다.
집계 함수에서의 NULL 처리
집계 함수(SUM, AVG, COUNT 등)는 NULL 값을 처리하는 방식이 제각각이므로 주의가 필요합니다.
* SUM(컬럼): NULL을 제외하고 합계를 구합니다.
* COUNT(*): NULL을 포함한 전체 행의 수를 셉니다.
* COUNT(컬럼): 해당 컬럼에 NULL이 있는 행은 제외하고 셉니다.
* AVG(컬럼): NULL인 행을 분모(건수)에서 제외하고 평균을 계산합니다. 이를 간과하면 평균값이 예상보다 높게 나올 수 있습니다.
NVL과 COALESCE 함수의 활용
문제에서는 NULL 값을 특정 값으로 치환하여 연산하는 시나리오가 자주 나옵니다. Oracle의 NVL(표현식1, 표현식2), NVL2(표현식1, 표현식2, 표현식3)와 SQL Server(MSSQL)의 ISNULL(표현식1, 표현식2)의 차이, 그리고 표준 SQL인 COALESCE의 작동 방식을 명확히 구분해야 합니다.
2. SQL 실행 순서 (Logical Execution Order)
SQL 문법을 아는 것과 엔진이 실제로 쿼리를 실행하는 순서를 아는 것은 별개입니다. 복잡한 쿼리의 결과나 오류 발생 원인을 묻는 문제에서 실행 순서는 결정적인 단서가 됩니다.
논리적 실행 단계
우리가 쿼리를 작성하는 순서(SELECT -> FROM -> WHERE…)와 달리, DBMS는 다음과 같은 순서로 데이터를 처리합니다.
- FROM: 대상 테이블을 참조합니다 (JOIN 포함).
- ON: JOIN 조건을 확인합니다.
- JOIN: 지정된 유형의 조인을 수행합니다.
- WHERE: 일반 조건으로 필터링합니다.
- GROUP BY: 데이터를 그룹화합니다.
- HAVING: 그룹화된 데이터에 조건을 적용합니다.
- SELECT: 최종적으로 출력할 컬럼을 선택합니다.
- DISTINCT: 중복을 제거합니다.
- ORDER BY: 정렬을 수행합니다.
Alias(별칭) 사용 시 주의점
이 실행 순서 때문에 SELECT 절에서 정의한 Alias를 WHERE 절에서는 사용할 수 없습니다. WHERE 절이 SELECT 절보다 먼저 실행되기 때문입니다. 반면, ORDER BY 절은 가장 마지막에 실행되므로 SELECT 절의 Alias를 사용할 수 있습니다. 이 규칙을 위반한 보기를 찾아내는 문제가 빈번하게 출제됩니다.
3. JOIN의 종류와 결과 집합(Result Set) 계산
JOIN은 두 개 이상의 테이블을 연결하여 데이터를 조회하는 핵심 기능입니다. 단순히 문법을 묻기보다는, 주어진 테이블 데이터를 바탕으로 JOIN 수행 후의 결과 건수를 계산하는 문제가 주로 나옵니다.
INNER JOIN과 OUTER JOIN의 차이
- INNER JOIN: 조인 조건이 일치하는 행만 반환합니다. 교집합 개념입니다.
- LEFT OUTER JOIN: 왼쪽 테이블의 모든 행을 반환하고, 오른쪽 테이블에 매칭되는 데이터가 없으면 NULL로 채웁니다.
카티션 곱 (Cartesian Product / CROSS JOIN)
조인 조건이 누락되었거나 의도적으로 CROSS JOIN을 수행했을 때 발생하는 현상입니다. A 테이블의 행이 N개, B 테이블의 행이 M개일 때 결과는 N * M개가 됩니다. 의도치 않은 데이터 증폭을 묻는 문제에서 자주 등장합니다.
코드 샘플: OUTER JOIN의 이해
다음은 고객(Customer)과 주문(Orders) 테이블을 이용한 OUTER JOIN 예시입니다. 주문 내역이 없는 고객도 조회하기 위해 LEFT JOIN을 사용합니다.
SELECT C.CustomerID, C.CustomerName, O.OrderID
FROM Customers C
LEFT JOIN Orders O
ON C.CustomerID = O.CustomerID;
-- 결과 해석:
-- CustomerID가 1인 고객이 주문이 없다면,
-- O.OrderID 컬럼에는 NULL이 출력됩니다.
-- INNER JOIN을 사용했다면 해당 고객은 결과 집합에서 아예 제외됩니다.
4. 집계 함수와 GROUP BY 절의 특징
데이터 분석의 기초가 되는 그룹핑 문제입니다. GROUP BY를 사용할 때 SELECT 리스트에 올 수 있는 컬럼의 제한 사항을 묻는 문제가 핵심입니다.
SELECT 리스트의 제약
GROUP BY 절을 사용하면, SELECT 절에는 GROUP BY에 명시된 컬럼이나 집계 함수(SUM, MAX 등)를 쓴 표현식만 올 수 있습니다. 그룹핑되지 않은 일반 컬럼을 단독으로 SELECT 하려고 하면 에러가 발생합니다.
HAVING 절의 역할
WHERE 절은 집계 전의 개별 행을 필터링하고, HAVING 절은 집계가 완료된 그룹을 필터링합니다. 예를 들어 “평균 급여가 5000 이상인 부서”를 찾으려면 WHERE가 아닌 HAVING AVG(SALARY) >= 5000을 사용해야 합니다.
5. 서브쿼리(Subquery)의 유형과 제약
서브쿼리는 SQLD의 난이도를 높이는 주범입니다. 위치에 따라 스칼라 서브쿼리, 인라인 뷰, 중첩 서브쿼리로 나뉘며 각각의 특징을 이해해야 합니다.
단일 행 vs 다중 행 서브쿼리
- 단일 행 서브쿼리: 결과가 1건 이하인 서브쿼리입니다. 단일 행 비교 연산자(
=,<,>)를 사용해야 합니다. - 다중 행 서브쿼리: 결과가 여러 건일 수 있습니다. 다중 행 연산자(
IN,ANY,ALL,EXISTS)를 사용해야 합니다.IN: 리스트 내의 값 중 하나라도 일치하면 참.ALL: 리스트의 모든 값과 조건이 일치해야 참.ANY: 리스트의 값 중 하나라도 조건이 일치하면 참.
6. 집합 연산자 (Set Operators)
두 개 이상의 쿼리 결과를 하나로 합치거나 빼는 연산입니다. 컬럼의 개수와 데이터 타입이 일치해야 한다는 전제 조건이 있습니다.
UNION과 UNION ALL의 결정적 차이
이 두 연산자의 차이는 ‘중복 제거’와 ‘정렬’에 있습니다.
* UNION: 두 결과 집합을 합친 후 중복된 행을 제거합니다. 이 과정에서 내부적으로 정렬(Sort) 작업이 발생하여 성능 부하가 생길 수 있습니다.
* UNION ALL: 중복을 제거하지 않고 단순히 두 결과를 붙여서 출력합니다. 정렬 과정이 없어 UNION보다 속도가 빠릅니다.
MINUS (EXCEPT)와 INTERSECT
- MINUS (Oracle) / EXCEPT (SQL Server): 차집합을 구합니다. 선행 쿼리 결과에서 후행 쿼리 결과를 뺍니다.
- INTERSECT: 교집합을 구합니다.
7. 윈도우 함수 (Window Functions)
최근 출제 비중이 급격히 늘어나고 있는 영역입니다. 행과 행 간의 관계를 정의하거나 순위를 매길 때 사용합니다. GROUP BY와 달리 행의 수가 줄어들지 않으면서 집계 정보를 함께 보여줍니다.
순위 함수 3대장 구분하기
비슷해 보이지만 순위를 매기는 방식이 다른 세 가지 함수를 구분하는 것이 핵심입니다.
- RANK: 동일한 값에 대해 같은 순위를 부여하며, 다음 순위는 건너뜁니다. (예: 1등, 1등, 3등)
- DENSE_RANK: 동일한 값에 대해 같은 순위를 부여하지만, 다음 순위를 건너뛰지 않습니다. (예: 1등, 1등, 2등)
- ROW_NUMBER: 동일한 값이라도 고유한 순위를 부여합니다. (예: 1등, 2등, 3등)
코드 샘플: 순위 함수 비교
SELECT Name, Salary,
RANK() OVER (ORDER BY Salary DESC) AS Rank_Val,
DENSE_RANK() OVER (ORDER BY Salary DESC) AS Dense_Rank_Val,
ROW_NUMBER() OVER (ORDER BY Salary DESC) AS Row_Num_Val
FROM Employees;
위 코드를 실행했을 때 Salary가 같은 사원들에 대해 각 함수가 어떤 값을 반환하는지 표로 그려보며 연습해야 합니다.
PARTITION BY와 ROWS/RANGE 절
OVER 절 내부의 PARTITION BY는 전체 집합을 소그룹으로 나누어 연산하게 하며, ROWS나 RANGE 절은 누적 합계 등을 구할 때 연산 범위를 지정합니다. 특히 UNBOUNDED PRECEDING (처음부터) 같은 키워드의 의미를 알아두어야 합니다.
8. 계층형 질의 (Hierarchical Query)
오라클 DB를 사용하는 환경에서 트리 구조(조직도, 카테고리 등)를 표현할 때 사용됩니다.
CONNECT BY 절의 동작 원리
- START WITH: 계층 구조의 시작점(루트 노드)을 지정합니다.
- CONNECT BY PRIOR 자식 = 부모: 부모에서 자식 방향으로 내려가는 순방향 전개입니다.
- CONNECT BY PRIOR 부모 = 자식: 자식에서 부모 방향으로 올라가는 역방향 전개입니다.
- LEVEL: 현재 계층의 깊이를 나타내는 의사 컬럼입니다.
PRIOR 키워드가 어느 쪽에 붙느냐에 따라 트리의 탐색 방향이 완전히 달라지므로, 이를 해석하는 능력이 필수적입니다.
9. 트랜잭션 제어 (TCL)와 데이터 무결성
데이터를 조작하는 DML(INSERT, UPDATE, DELETE) 이후의 처리 과정입니다.
COMMIT과 ROLLBACK
- COMMIT: 변경 사항을 데이터베이스에 영구적으로 반영합니다.
- ROLLBACK: 변경 사항을 취소하고 마지막 커밋 시점으로 되돌립니다.
- SAVEPOINT: 롤백할 수 있는 중간 지점을 설정합니다.
Auto Commit 여부
SQL Server는 기본적으로 Auto Commit이 활성화되어 있고, Oracle은 명시적으로 COMMIT을 해야 한다는 차이점을 묻기도 합니다. 트랜잭션의 특징인 ACID(원자성, 일관성, 고립성, 지속성)의 개념을 묻는 이론 문제도 대비해야 합니다.
10. 문자열 및 날짜 변환 함수
다양한 데이터 타입을 다루는 능력, 특히 형 변환 함수에 대한 이해도를 평가합니다.
형 변환 함수
- TO_CHAR: 날짜나 숫자를 문자로 변환합니다. 날짜 포맷(
YYYY-MM-DD HH24:MI:SS) 지정 방식이 자주 출제됩니다. - TO_DATE: 문자를 날짜로 변환합니다.
- TO_NUMBER: 문자를 숫자로 변환합니다.
조건부 표현식 CASE WHEN
프로그래밍의 IF-ELSE 구문과 유사한 CASE WHEN은 두 가지 형식이 있습니다.
1. Simple Case Expression: CASE 컬럼 WHEN 값 THEN 결과 (등호 비교만 가능)
2. Searched Case Expression: CASE WHEN 조건 THEN 결과 (부등호 등 복잡한 조건 가능)
ELSE 절을 생략하면 조건에 맞지 않는 경우 NULL이 반환된다는 점을 기억하세요.
SQLD 자격증 시험은 단순히 문법을 암기했는지 확인하는 것이 아니라, 주어진 SQL이 데이터베이스 내부에서 어떻게 동작하고 결과 데이터가 어떻게 변형되는지를 논리적으로 추론할 수 있는지를 평가합니다. 위에서 다룬 TOP 10 유형은 매 회차 시험마다 형태만 조금씩 바뀌어 반드시 출제되는 핵심 영역입니다.
특히 NULL 처리, JOIN 결과 건수 계산, 순위 함수는 변별력을 가르는 고배점 문제로 자주 등장하므로, 직접 DBMS를 설치하거나 온라인 SQL 연습 사이트를 통해 코드를 실행해 보며 체득하는 것을 강력히 권장합니다.