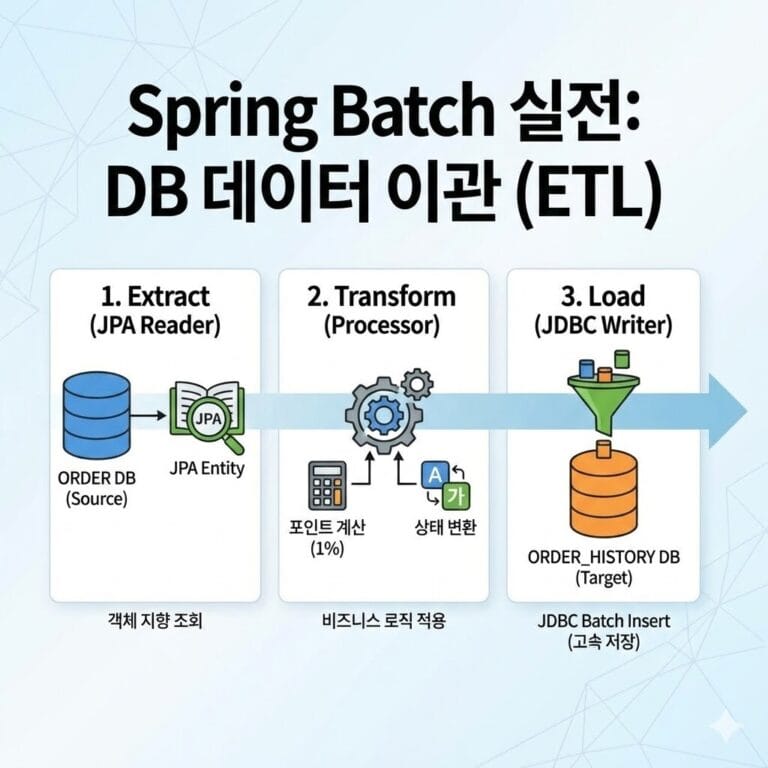
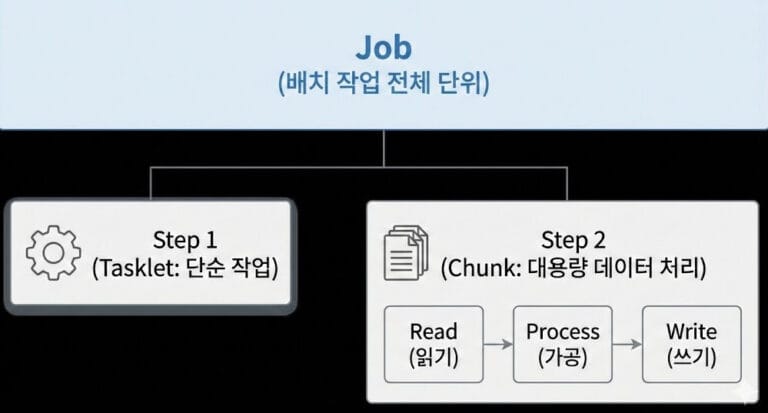
안녕하세요, Code Camp 독자 여러분! 오늘은 엔터프라이즈 환경의 꽃이라 불리는 Spring Batch의 성능 최적화(Performance Tuning)에 대해 심도 있게 다뤄보고자 합니다.
단순히 배치를 ‘돌리는’ 것을 넘어, 어떻게 하면 수천만 건의 데이터를 제한된 시간(Batch Window) 내에 안전하고 빠르게 처리할 수 있을까요? 5,000자 이상의 상세한 가이드를 통해 그 해답을 찾아보겠습니다.
목차
- 배치의 성능, 왜 중요한가?
- Chunk Size와 Page Size의 비밀
- Reader 성능 최적화: Cursor vs Paging
- Writer 성능 최적화: JdbcBatchItemWriter의 힘
- 병렬 처리 전략: Multi-threaded Step & Partitioning
- 실무 트러블슈팅: Deadlock과 성능 저하 해결하기
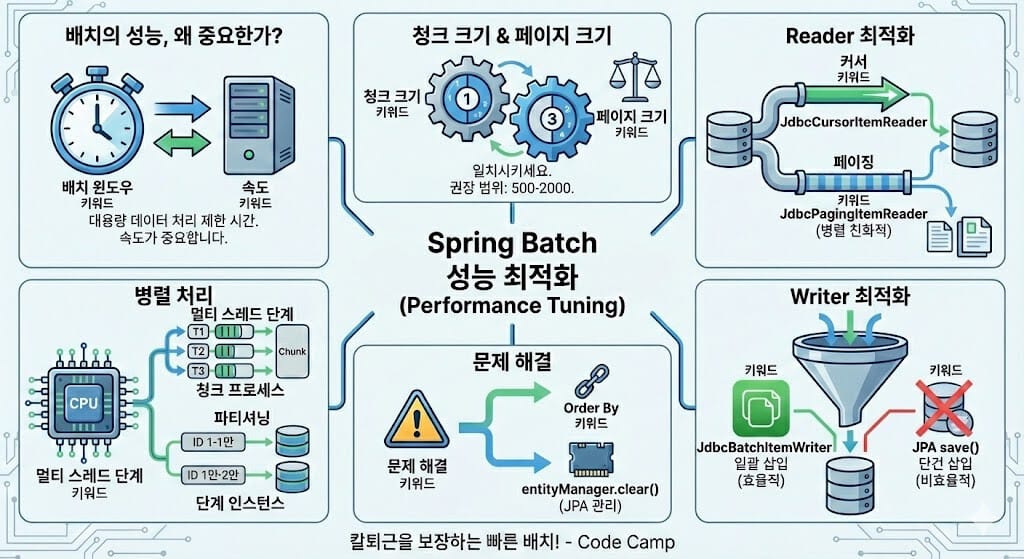
1. 배치의 성능, 왜 중요한가?
현대의 데이터 환경은 기하급수적으로 늘어나고 있습니다. 하지만 배치가 돌아갈 수 있는 시간은 보통 사용자가 적은 새벽 시간대인 ‘Batch Window’로 제한되어 있죠. 만약 정산 배치가 8시간 안에 끝나지 않아 다음 날 업무 시작 시간까지 이어진다면 어떻게 될까요? 서비스 장애로 이어지는 심각한 상황이 발생합니다.
따라서 배치는 ‘정확성’만큼이나 ‘속도’가 중요합니다.
2. Chunk Size와 Page Size의 비밀
Spring Batch 성능 튜닝의 시작이자 끝은 Chunk Size 설정입니다.
Chunk Size란?
한 번에 트랜잭션에 커밋되는 단위입니다.
– 너무 작으면: 빈번한 트랜잭션 커밋으로 인해 네트워크 오버헤드가 발생합니다.
– 너무 크면: 메모리 부족(OutOfMemory)이 발생하거나, 실패 시 롤백되는 데이터가 너무 많아 복구 시간이 길어집니다.
Page Size와의 관계
PagingReader를 사용한다면 Page Size와 Chunk Size를 반드시 일치시키는 것이 좋습니다.
– 만약 Page Size는 10인데 Chunk Size가 100이라면, 한 번의 Chunk를 채우기 위해 10번의 Select 쿼리가 나갑니다. 이는 비효율적입니다.
실무 추천: 보통 500에서 2,000 사이에서 최적의 지점을 찾으세요. JPA를 사용한다면 영속성 컨텍스트 관리를 위해 500 이하를 추천하며, JDBC를 사용한다면 1,000 이상도 무방합니다.
3. Reader 성능 최적화: Cursor vs Paging
데이터를 읽어오는 방식에 따라 성능 차이가 확연합니다.
Cursor 방식 (JdbcCursorItemReader)
- 원리: DB와 커넥션을 맺고 데이터를 하나씩 스트리밍 방식으로 읽어옵니다.
- 장점: Paging 방식보다 빠릅니다. (Limit/Offset 연산이 없기 때문)
- 단점: 데이터 처리 시간이 너무 길어지면 Socket Timeout이 발생하거나 DB 커넥션을 너무 오래 점유합니다.
Paging 방식 (JdbcPagingItemReader)
- 원리:
LIMIT,OFFSET을 사용하여 페이지 단위로 읽어옵니다. - 장점: 커넥션을 짧게 유지하며 병렬 처리에 유리합니다.
- 단점: 페이지 번호가 뒤로 갈수록 DB에서 데이터를 찾는 속도가 느려질 수 있습니다. (Deep Offset 문제)
팁: 단일 스레드 작업이라면 Cursor가 빠르지만, 대규모 병렬 처리가 필요하다면 Paging 방식을 선택하세요.
4. Writer 성능 최적화: JdbcBatchItemWriter의 힘
대부분의 배치 성능 병목은 Writer에서 발생합니다. 특히 JPA의 save() 메서드는 단건으로 Insert/Update를 수행하므로 대용량 처리에는 치명적입니다.
Bad Case: JPA save()
// 하나씩 insert 쿼리가 나감 (비효율적)
repository.save(item);
Good Case: JdbcBatchItemWriter
@Bean
public JdbcBatchItemWriter<User> userWriter() {
return new JdbcBatchItemWriterBuilder<User>()
.dataSource(dataSource)
.sql("INSERT INTO users (name, email) VALUES (:name, :email)")
.beanMapped()
.build();
}
JDBC의 addBatch()와 executeBatch() 기능을 사용하여 1,000건의 데이터를 단 한 번의 네트워크 요청으로 DB에 쏟아붓습니다. 성능이 수십 배 차이 날 수 있습니다.
5. 병렬 처리 전략
서버의 CPU 자원을 풀(Full)로 활용하고 싶다면 병렬 처리는 필수입니다.
Multi-threaded Step
- 한 개의 Step 안에서 여러 스레드가 Chunk를 나누어 처리합니다.
- 주의: 사용 중인 Reader가 Thread-safe한지 반드시 확인해야 합니다. (JdbcPagingItemReader는 safe하지만, JdbcCursorItemReader는 아닙니다.)
Partitioning (마스터-슬레이브)
- 데이터를 특정 범위(ID 1~10000, 10001~20000 등)로 나누어 별도의 Step 인스턴스로 실행합니다.
- 가장 강력한 성능을 발휘하며, 여러 대의 서버로 확장(Remote Partitioning)도 가능합니다.
6. 실무 트러블슈팅
Deadlock(데드락) 해결하기
병렬 배치를 돌릴 때 같은 테이블을 업데이트하다 보면 데드락이 발생할 수 있습니다.
– 해결책: 데이터를 읽어올 때 ID 순서로 정렬(Order By)하여 읽어오도록 설정하면 락 경쟁 순서가 일정해져 데드락을 방지할 수 있습니다.
영속성 컨텍스트 비우기
JPA를 사용한다면 Chunk가 끝날 때마다 entityManager.clear()를 호출하여 메모리 누수를 방지하세요. Spring Batch의 JpaItemWriter가 이 작업을 자동으로 해주지만, 커스텀 로직을 쓸 때는 주의해야 합니다.
마치며
오늘 다룬 성능 최적화 기법들은 실제 수억 건의 데이터를 다루는 금융권이나 커머스 환경에서 검증된 패턴들입니다.
- Chunk Size를 최적화하세요.
- JdbcBatchItemWriter를 적극 활용하세요.
- 병렬 처리를 통해 서버 자원을 효율적으로 쓰세요.
여러분의 배치가 ‘칼퇴근’을 보장하는 빠른 배치가 되길 바랍니다!
다음 시간에는 Spring Batch의 테스트 전략에 대해 심도 있게 다뤄보겠습니다.
오늘 글이 도움이 되셨다면 댓글과 공유 부탁드립니다!
Code Camp 드림.