안녕하세요. 실무에 바로 쓰이는 IT 기술을 전하는 Code Camp입니다.
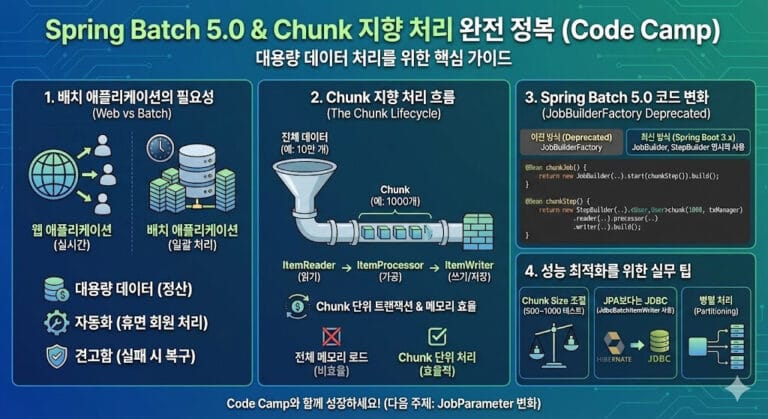
백엔드 개발자로 성장하다 보면 반드시 마주치는 거대한 산이 있습니다. 바로 ‘대용량 데이터 처리’입니다. 수백만 건의 결제 데이터를 정산하거나, 매일 밤 전송되는 로그를 분석해 통계를 내는 작업은 일반적인 웹 API 방식으로는 불가능합니다. 이때 등장하는 구원투수가 바로 Spring Batch입니다.
오늘은 Spring Batch를 지탱하는 4가지 핵심 기둥인 Job, Step, ItemReader, ItemWriter에 대해 아주 상세하게 파헤쳐 보겠습니다. 이 글 하나만 정독하셔도 Spring Batch의 전체적인 설계도를 머릿속에 그리실 수 있을 겁니다.
1. Spring Batch란 무엇인가?
핵심 구성요소를 알아보기에 앞서, 왜 Spring Batch를 써야 하는지 짧게 짚고 넘어가겠습니다.
- 대용량 처리: 메모리 한계를 극복하기 위해 데이터를 나누어 읽고 쓰는(Chunk) 구조를 기본적으로 제공합니다.
- 견고함: 작업 중 실패했을 때 어디서부터 다시 시작해야 하는지, 몇 번 재시도했는지 등 상태를 관리합니다.
- 신뢰성: 트랜잭션 관리가 자동화되어 있어 데이터 무결성을 보장합니다.
이제 이 기능을 가능하게 하는 구성요소들을 하나씩 살펴보겠습니다.
2. Job: 배치 작업의 사령관
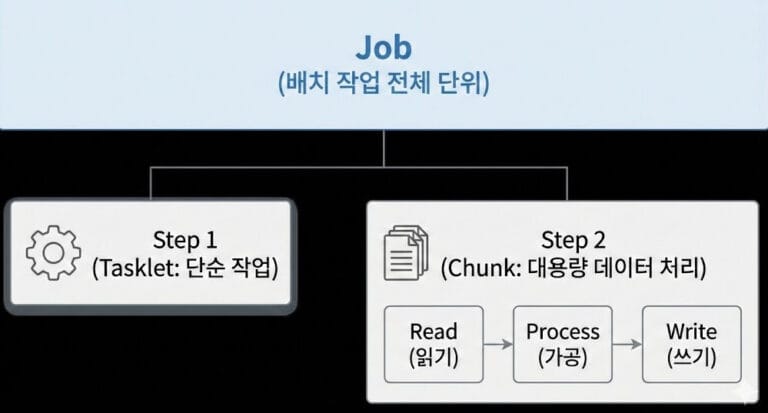
Job은 배치 처리의 전체 작업 단위입니다. 우리가 “오늘자 정산 배치를 돌려라”라고 할 때, 그 ‘정산 배치’가 바로 Job입니다.
2.1 Job의 구조
Job은 하나 이상의 Step으로 구성됩니다. 마치 ‘라면 끓이기(Job)’가 ‘물 끓이기(Step 1)’, ‘면 넣기(Step 2)’, ‘계란 넣기(Step 3)’로 이루어진 것과 같습니다. Spring Batch에서는 이 Step들을 순차적으로 실행하거나, 조건에 따라 분기 처리를 할 수 있습니다.
2.2 JobInstance vs JobExecution (★ 중요)
Spring Batch 면접에서 가장 많이 나오는 질문 중 하나입니다. 이 둘의 차이를 명확히 아는 것이 중요합니다.
- JobInstance: Job의 논리적 실행 단위입니다.
- 예:
DailySettlementJob(일일 정산)이 있다고 합시다. ‘2023-10-25’일자 정산, ‘2023-10-26’일자 정산은 각각 다른 JobInstance입니다. - 식별: Job 이름 + Job Parameter(날짜 등)의 조합으로 유니크하게 식별됩니다.
- 예:
- JobExecution: JobInstance의 실제 실행 시도(Attempt)입니다.
- ‘2023-10-25’일자 정산을 실행했는데 실패했다고 가정해 봅시다. 오류를 수정하고 다시 실행합니다.
- 이때 JobInstance는 1개이지만, JobExecution은 2개(첫 번째 실패, 두 번째 성공)가 생성됩니다.
2.3 Job 설정 예제 코드
@Configuration
@RequiredArgsConstructor
public class SettlementJobConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
@Bean
public Job settlementJob() {
return new JobBuilder("settlementJob", jobRepository)
.start(validationStep()) // 첫 번째 단계: 데이터 검증
.next(calculationStep()) // 두 번째 단계: 정산 계산
.next(reportStep()) // 세 번째 단계: 리포트 생성
.build();
}
// ... Step 정의 생략
}
Expert Tip: Job의 이름은 시스템 전체에서 유일해야 하며, 유지보수를 위해 명확한 네이밍 컨벤션(예:
업무명_Job)을 따르는 것이 좋습니다.
3. Step: 실질적인 일꾼
Step은 Job 내부에서 실제로 비즈니스 로직을 수행하는 독립적인 단계입니다. Job이 전체적인 흐름을 제어하는 감독관이라면, Step은 묵묵히 맡은 일을 처리하는 작업자입니다.
3.1 Step의 두 가지 방식
Spring Batch의 Step은 크게 두 가지 구현 방식을 가집니다.
- Tasklet 방식: 단순한 작업에 적합합니다. (예: 파일 삭제, 이메일 전송, 단순 쿼리 실행)
- Chunk 지향 방식: 대용량 데이터 처리에 최적화되어 있습니다. (예: 100만 건 데이터 읽기 -> 가공 -> 쓰기)
3.2 Tasklet vs Chunk 코드 비교
[Case 1: Tasklet – 단순 파일 삭제]
@Bean
public Step deleteTempFileStep() {
return new StepBuilder("deleteTempFileStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
File file = new File("C:\\temp\\data.csv");
if (file.exists()) {
file.delete();
}
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
[Case 2: Chunk – 대용량 데이터 처리]
@Bean
public Step processUserStep() {
return new StepBuilder("processUserStep", jobRepository)
.<User, UserGrade>chunk(100, transactionManager) // 100개 단위로 커밋
.reader(userReader())
.processor(userGradeProcessor())
.writer(userGradeWriter())
.build();
}
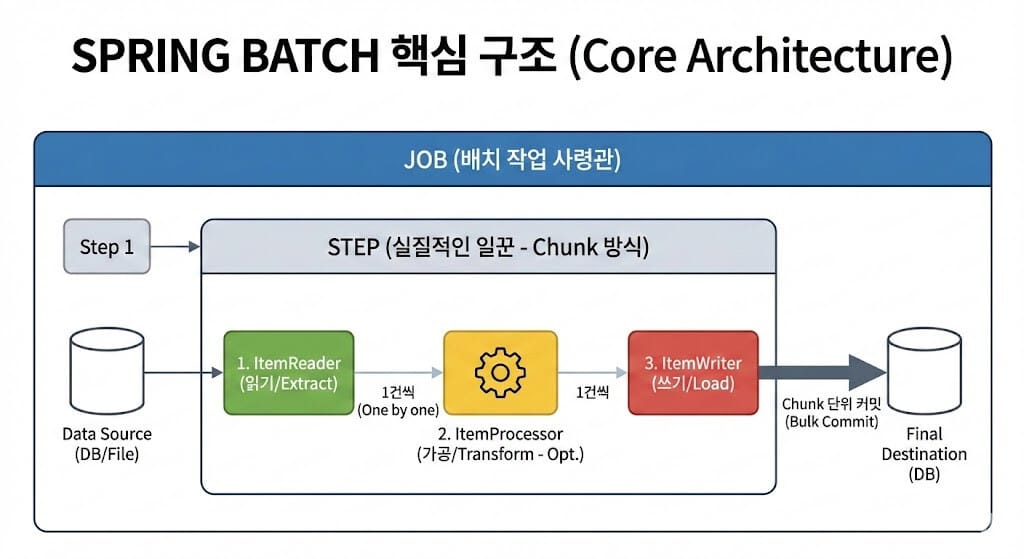
4. ItemReader, ItemProcessor, ItemWriter (Chunk Model)
Chunk 지향 처리의 핵심 3인방입니다. 이들은 ETL (Extract, Transform, Load) 패턴과 정확히 매칭됩니다.
4.1 ItemReader (Extract)
데이터 소스(DB, File, Kafka 등)에서 데이터를 읽어옵니다.
* 핵심 기능: 데이터를 하나씩 읽어 반환하며, 더 이상 읽을 데이터가 없으면 null을 반환하여 Step을 종료시킵니다.
* Cursor vs Paging: DB에서 데이터를 읽을 때, 전체 데이터를 메모리에 올리지 않기 위해 커서나 페이징 기법을 사용합니다. Spring Batch는 JdbcCursorItemReader, JpaPagingItemReader 등 강력한 구현체를 제공합니다.
4.2 ItemProcessor (Transform) – Optional
Reader에서 읽어온 데이터를 가공하거나 필터링합니다. 필수는 아니지만, 비즈니스 로직을 분리하기 위해 적극 권장됩니다.
* 변환: User 엔티티를 읽어서 UserGrade DTO로 변환.
* 필터링: 특정 조건(예: 휴면 계정)에 해당하면 null을 반환하여 Writer로 넘기지 않음.
4.3 ItemWriter (Load)
가공된 데이터를 최종 목적지에 저장합니다.
* 특징: Reader와 Processor가 데이터를 하나씩 처리하는 것과 달리, Writer는 Chunk 단위로 묶인 List를 전달받아 한 번에 처리합니다. 이를 통해 Bulk Insert가 가능해져 성능이 비약적으로 향상됩니다.
4.4 사용자 등급 산정 예제 코드
이 예제는 30일 이상 로그인하지 않은 사용자를 찾아 ‘휴면(Dormant)’ 상태로 변경하는 로직입니다.
@Bean
public ItemReader<User> dormantUserReader() {
return new JpaPagingItemReaderBuilder<User>()
.name("dormantUserReader")
.entityManagerFactory(entityManagerFactory)
.pageSize(100)
.queryString("SELECT u FROM User u WHERE u.lastLogin < :standardDate AND u.status = 'ACTIVE'")
.parameterValues(Map.of("standardDate", LocalDate.now().minusDays(30)))
.build();
}
@Bean
public ItemProcessor<User, User> dormantUserProcessor() {
return user -> {
// 비즈니스 로직: 상태 변경
user.setStatus(UserStatus.DORMANT);
return user;
};
}
@Bean
public ItemWriter<User> dormantUserWriter() {
return users -> {
// JPA를 사용하면 Dirty Checking으로 별도 save 호출이 필요 없을 수 있지만,
// 명시적인 저장을 위해 Repository 호출
userRepository.saveAll(users);
System.out.println(users.size() + "명의 사용자가 휴면 처리되었습니다.");
};
}
5. 결론 및 요약
Spring Batch는 단순한 라이브러리가 아닙니다. 수십 년간 축적된 엔터프라이즈 데이터 처리의 노하우가 집약된 프레임워크입니다.
- Job: 배치의 실행 단위 (JobInstance, JobExecution 개념 필히 숙지!)
- Step: 실제 작업의 단계 (Tasklet vs Chunk)
- Reader/Processor/Writer: 데이터를 읽고, 가공하고, 쓰는 효율적인 파이프라인
오늘 배운 이 4가지 구성요소만 완벽히 이해해도, 여러분은 이미 배치 애플리케이션을 설계할 준비가 된 것입니다. 다음 시간에는 이들이 실제로 어떻게 움직이는지, Step Lifecycle과 트랜잭션 관리에 대해 심도 있게 다뤄보겠습니다.
여러분의 성장하는 개발 라이프를 응원합니다!