안녕하세요, Code Camp 독자 여러분!
오늘은 엔터프라이즈 애플리케이션에서 빼놓을 수 없는 Spring Batch, 그중에서도 핵심인 Chunk 지향 처리(Chunk-oriented Processing)에 대해 알아보겠습니다.
특히 Spring Boot 3.x로 넘어오면서 Spring Batch 5.0에 많은 변화가 있었는데요, 최신 트렌드에 맞춰 어떻게 대용량 데이터를 효율적으로 처리할 수 있는지 실무 관점에서 정리해 드립니다.
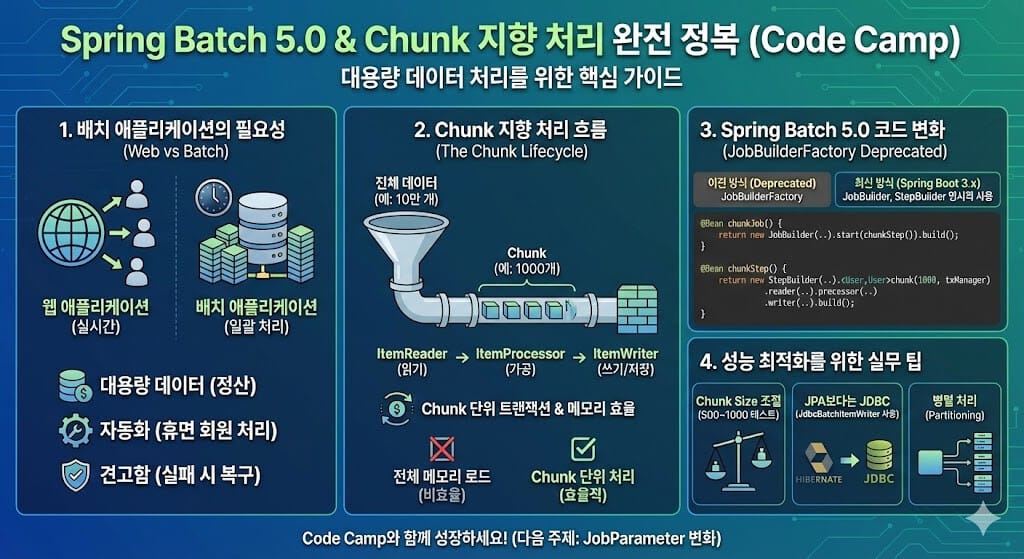
1. 배치 애플리케이션, 왜 필요할까요?
웹 애플리케이션이 사용자의 요청에 ‘실시간’으로 응답하는 것이라면, 배치 애플리케이션은 정해진 시간에, 대량의 데이터를, 일괄적으로 처리하는 것을 목표로 합니다.
- 대용량 데이터: 수백만 건의 결제 내역을 정산할 때
- 자동화: 매일 밤 12시에 휴면 회원을 처리할 때
- 견고함: 처리 중 실패하더라도 어디서부터 다시 시작해야 할지 알 수 있어야 함
Spring Batch는 이러한 요구사항을 완벽하게 충족시켜주는 프레임워크입니다.
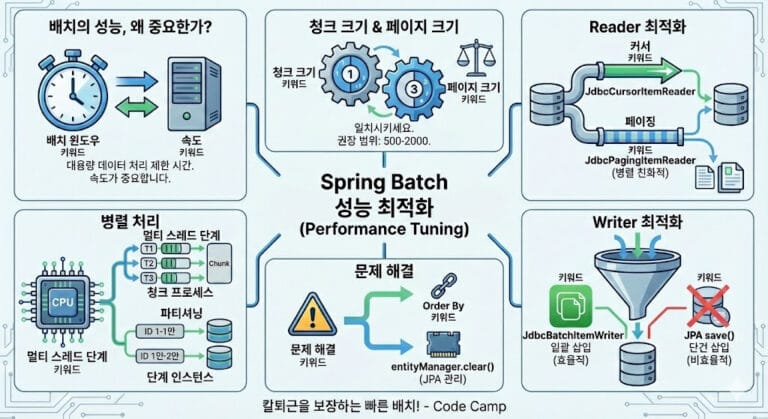
2. Chunk 지향 처리란?
Spring Batch의 가장 큰 특징은 Chunk(덩어리) 단위로 데이터를 처리한다는 점입니다.
10만 개의 데이터를 처리해야 한다면, 10만 개를 한 번에 메모리에 올리는 것이 아니라 1000개씩(Chunk Size) 끊어서 읽고, 가공하고, 저장합니다.
처리 흐름 (The Chunk Lifecycle)
- ItemReader: 데이터를 하나씩 읽어옵니다. (DB, 파일 등)
- ItemProcessor: 읽어온 데이터를 가공합니다. (필터링, 변환)
- ItemWriter: 가공된 데이터를 Chunk 단위(예: 1000개)로 모아 한 번에 씁니다. (Batch Insert)
이 방식 덕분에 메모리 효율이 매우 뛰어나며, 트랜잭션 관리도 Chunk 단위로 이루어져 실패 시 복구가 용이합니다.
3. Spring Batch 5.0 코드로 구현하기
Spring Batch 5.0(Spring Boot 3.x)부터는 JobBuilderFactory, StepBuilderFactory가 Deprecated 되었고, 명시적으로 Builder를 생성해야 합니다.
@Configuration
@RequiredArgsConstructor
public class ChunkBatchConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
@Bean
public Job chunkJob() {
return new JobBuilder("chunkJob", jobRepository)
.start(chunkStep())
.build();
}
@Bean
public Step chunkStep() {
return new StepBuilder("chunkStep", jobRepository)
.<User, User>chunk(1000, transactionManager) // Chunk Size: 1000
.reader(userReader())
.processor(userProcessor())
.writer(userWriter())
.build();
}
// ... Reader, Processor, Writer 구현 빈(Bean)들은 생략
}
4. 성능 최적화를 위한 팁
Chunk 지향 처리를 사용할 때 성능을 더 끌어올리고 싶다면 다음을 고려해 보세요.
- 적절한 Chunk Size 찾기: 무조건 크다고 좋은 게 아닙니다. DB 커넥션 풀과 메모리 상황에 맞춰 500~1000 사이에서 테스트해보세요.
- JPA보다는 JDBC: 대량 데이터 처리 시 JPA(Hibernate)는 영속성 컨텍스트 관리 비용이 듭니다.
JdbcBatchItemWriter를 사용하면 성능이 훨씬 빠릅니다. - 병렬 처리(Parallel Processing): 데이터가 너무 많다면 파티셔닝(Partitioning) 기능을 이용해 여러 스레드에서 동시에 처리하도록 구성할 수 있습니다.
마치며
Spring Batch는 단순한 라이브러리가 아니라, 배치 처리를 위한 표준 아키텍처를 제공합니다. 오늘 소개한 Chunk 지향 처리를 잘 이해한다면, 수천만 건의 데이터도 두렵지 않을 것입니다.
다음 시간에는 Spring Batch 5.0에서의 JobParameter 변화에 대해 다뤄보겠습니다.
Code Camp와 함께 성장하는 하루 되세요!