안녕하세요.
현업에서 배치 작업을 수행할 때 가장 많이 마주하는 시나리오 중 하나가 바로 “파일 데이터를 DB로 마이그레이션” 하는 것입니다. 특히 엑셀에서 변환된 CSV 파일은 데이터 교환의 표준처럼 사용되죠.
오늘은 수만 건의 데이터를 담은 CSV 파일을 Spring Batch를 이용해 메모리 효율적으로 읽고, DB에 Bulk Insert 하는 전체 과정을 아주 상세하게 다뤄보겠습니다.
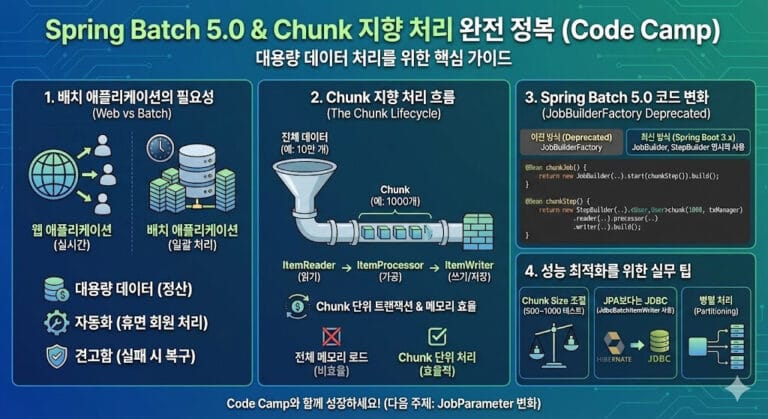
1. CSV to DB 처리 아키텍처
Spring Batch의 Chunk 지향 프로세스를 활용하면 대용량 CSV 처리도 매우 간단합니다.
- ItemReader:
FlatFileItemReader를 사용하여 CSV 파일의 각 라인을 객체(DTO)로 매핑합니다. - ItemProcessor: 읽어온 데이터의 유효성을 검증하거나 필요한 가공 처리를 수행합니다. (Optional)
- ItemWriter:
JdbcBatchItemWriter를 사용하여 Chunk 단위로 DB에 저장합니다.

위 아키텍처의 핵심은 “스트리밍”입니다. 파일을 통째로 메모리에 올리는 것이 아니라, 한 줄씩 읽어서 처리하기 때문에 파일 용량이 기가바이트(GB) 단위여도 서버는 안전하게 동작합니다.
2. 실전 예제: 회원 가입 목록 CSV 적재
우리의 목표는 users.csv 파일을 읽어서 USER 테이블에 저장하는 것입니다.
2.1 CSV 데이터 구조 (users.csv)
id,name,email,age
1,홍길동,hong@example.com,30
2,김철수,kim@example.com,25
3,이영희,lee@example.com,28
2.2 도메인 객체 및 테이블 (Entity & DTO)
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class UserDto {
private Long id;
private String name;
private String email;
private int age;
}
3. 핵심 소스 코드 (1): Batch Job 설정
Spring Batch 5.x 스타일의 설정 코드입니다. FlatFileItemReader의 섬세한 설정법을 주목해 주세요.
@Configuration
@RequiredArgsConstructor
public class CsvToDbJobConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final DataSource dataSource;
@Bean
public Job csvToDbJob() {
return new JobBuilder("csvToDbJob", jobRepository)
.start(csvToDbStep())
.build();
}
@Bean
public Step csvToDbStep() {
return new StepBuilder("csvToDbStep", jobRepository)
.<UserDto, UserDto>chunk(100, transactionManager)
.reader(csvReader())
.writer(dbWriter())
.build();
}
@Bean
public FlatFileItemReader<UserDto> csvReader() {
return new FlatFileItemReaderBuilder<UserDto>()
.name("userCsvReader")
.resource(new ClassPathResource("users.csv")) // 파일 경로
.delimited() // 구분자로 분리된 파일 (CSV)
.names("id", "name", "email", "age") // 컬럼명 매핑
.fieldSetMapper(new BeanWrapperFieldSetMapper<>() {{
setTargetType(UserDto.class); // DTO 클래스 지정
}})
.linesToSkip(1) // 첫 줄(헤더) 건너뛰기
.build();
}
@Bean
public JdbcBatchItemWriter<UserDto> dbWriter() {
return new JdbcBatchItemWriterBuilder<UserDto>()
.dataSource(dataSource)
.sql("INSERT INTO USER (id, name, email, age) VALUES (:id, :name, :email, :age)")
.beanMapped() // DTO의 필드명과 SQL 파라미터(:id 등) 자동 매핑
.build();
}
}
4. 핵심 소스 코드 (2): 데이터 검증 및 변환 (Processor)
단순 적재가 아니라, 이메일 형식을 체크하거나 특정 나이 미만은 제외하고 싶다면 ItemProcessor를 추가합니다.
@Bean
public ItemProcessor<UserDto, UserDto> userProcessor() {
return item -> {
// 1. 유효성 검증: 이메일에 @가 없으면 무시
if (!item.getEmail().contains("@")) {
return null; // null 반환 시 해당 아이템은 Writer로 넘어가지 않음
}
// 2. 데이터 가공: 이름을 모두 대문자로 변경 (예시)
item.setName(item.getName().toUpperCase());
return item;
};
}
5. 주요 설정 포인트 (Deep Dive)
5.1 FlatFileItemReader의 강력함
CSV 파일은 단순히 쉼표로만 구분되지 않는 경우가 많습니다. 따옴표(")로 감싸진 필드나, 탭()으로 구분된 파일도 delimited() 설정만 바꾸면 모두 대응 가능합니다. 또한 파일이 깨져있을 경우 DefaultLineMapper를 커스텀하여 예외 처리를 정교하게 할 수 있습니다.
5.2 JdbcBatchItemWriter와 성능
왜 JpaItemWriter가 아니라 JdbcBatchItemWriter를 썼을까요?
JPA는 영속성 컨텍스트 관리 비용이 발생하지만, JDBC Batch Writer는 JDBC의 addBatch(), executeBatch() 기능을 사용하여 대량의 Insert 쿼리를 한 번에 날립니다. 대량 적재 성능 면에서 압도적으로 유리합니다.
6. 결론 및 팁
CSV 파일을 읽어 DB에 저장하는 배치는 간단해 보이지만, “에러 데이터 처리”가 가장 큰 숙제입니다.
- Skip 설정: 파일 중간에 한 줄이 깨져있다고 전체 배치를 멈추지 마세요.
faultTolerant().skip(FlatFileParseException.class).skipLimit(10)설정을 통해 유연하게 대처하세요. - 파일 인코딩: 한글이 깨진다면
encoding("UTF-8")혹은encoding("EUC-KR")설정을 잊지 마세요.
이제 이 예제를 바탕으로 여러분의 프로젝트에 강력한 데이터 이관 기능을 추가해 보세요! 기술적인 질문은 언제나 환영입니다.